


Credit: M Rizky Satrio, Alif Ramadhan
To keep up with evolving cybersecurity threats, we are exploring innovative solutions. Self-hosted Large Language Models (LLMs) are being considered for its potential to improve threat analysis and provide organizations with greater data control and security.
We have been conducting practical experiments to explore the product of LLMs. This article will present two of these experiments.
First, we developed an LLM chatbot using Spring Boot to assess its potential for conversational AI in a Java environment.
Second, we built a Retrieval-Augmented Generation (RAG) system, utilizing FastAPI, MongoDB, Qdrant, and the Groq LLM.
We will describe the technical aspects from each project, providing an overview of our design and implementation.
LLM Chatbot using Spring Boot
The goal of this project was to create a straightforward Spring Boot app that leverages self-hosted LLM for conversational interactions. We utilized the LlmCpp-Java library, a Java Native Interface (JNI) binding for llama.cpp, to bridge the gap between Java and the C++-based LLM inference engine.
Initially, the system undergoes an initialization phase where the LLM environment is established. This involves loading a pre-trained LLM, specifically in the GGUF format. The path to this model is dynamically specified through the -Dllamacpp.model system property, allowing for runtime model selection. Furthermore, several runtime configured to optimized performance and control the LLM's behavior:
- Temperature: set to 0.2 by default, controls the randomness of the model's responses. A lower temperature results in more deterministic outputs, while a higher temperature increases creativity.
- CPU Thread Allocation: allocates CPU threads for parallel processing, maximizing the efficiency of the LLM inference.
- Context Window Size: determines the amount of conversation history the model retains, impacting its ability to maintain context over longer interactions.
After the app's initialization, users can interact directly with the LLM through a simple command-line interface (CLI).
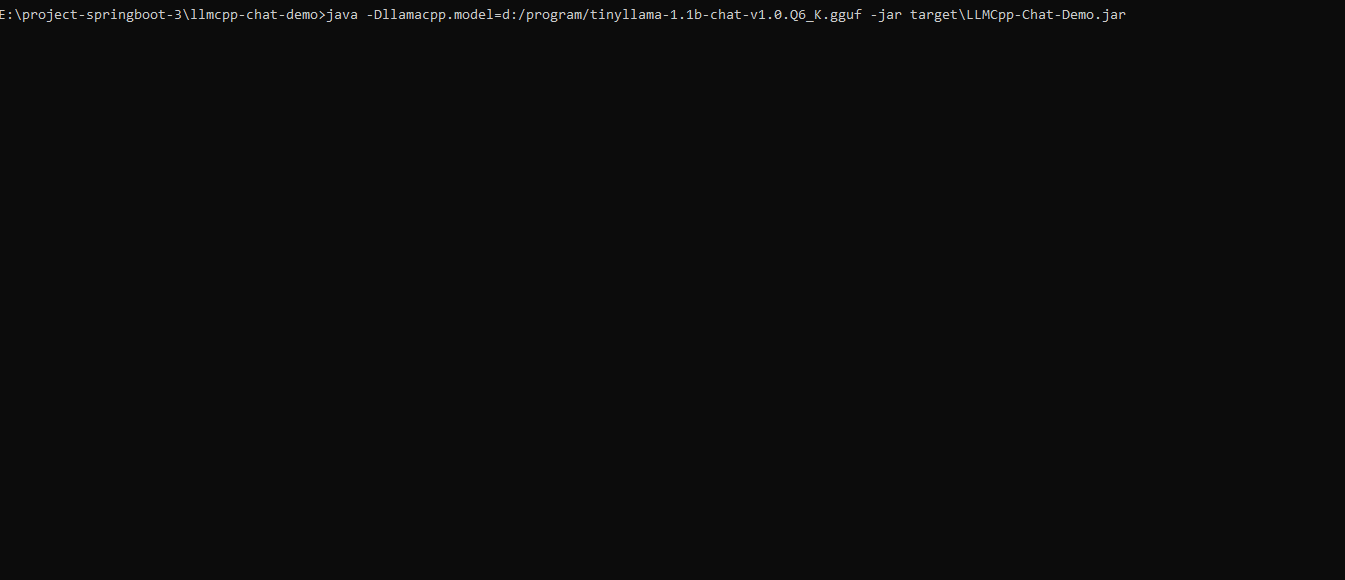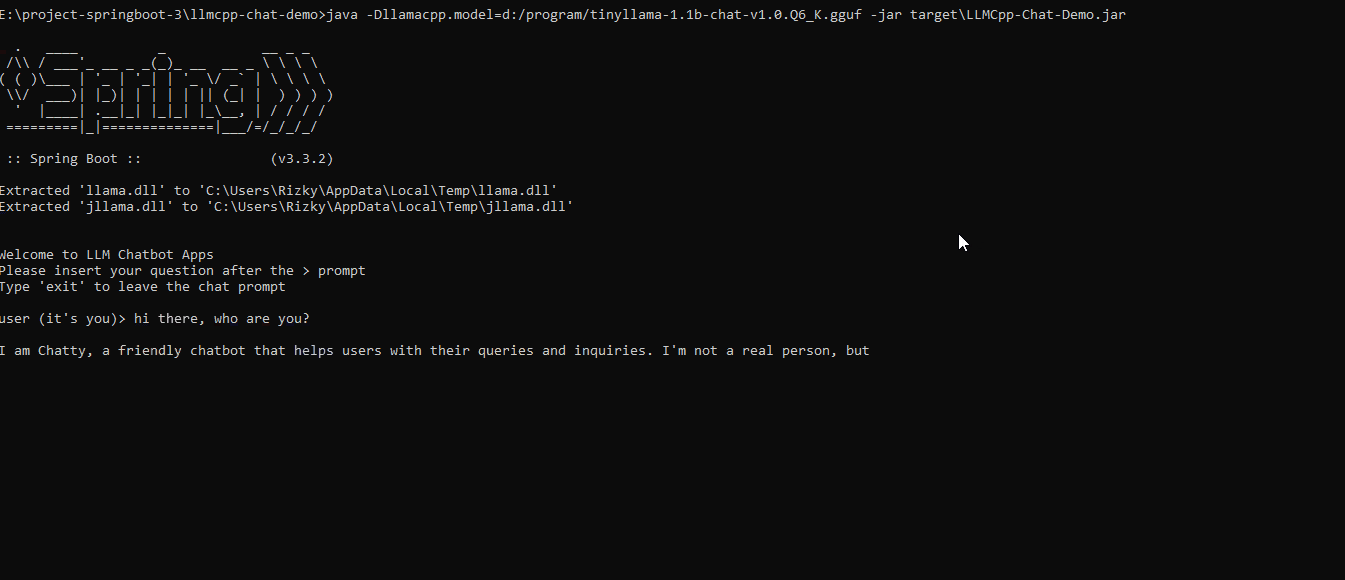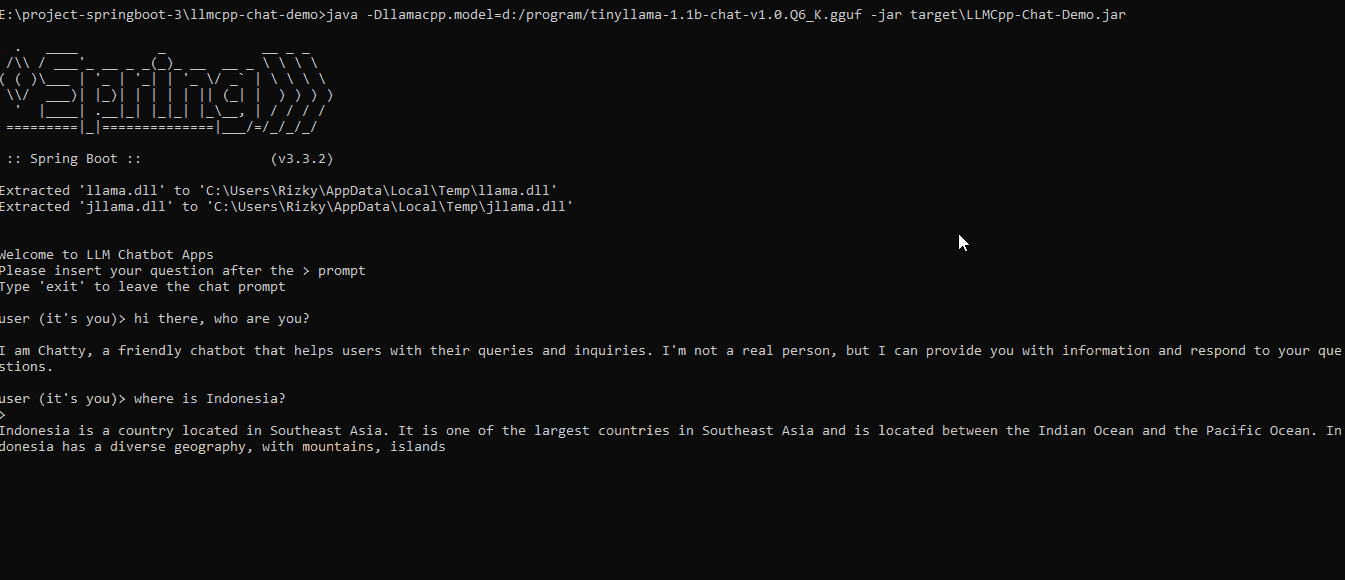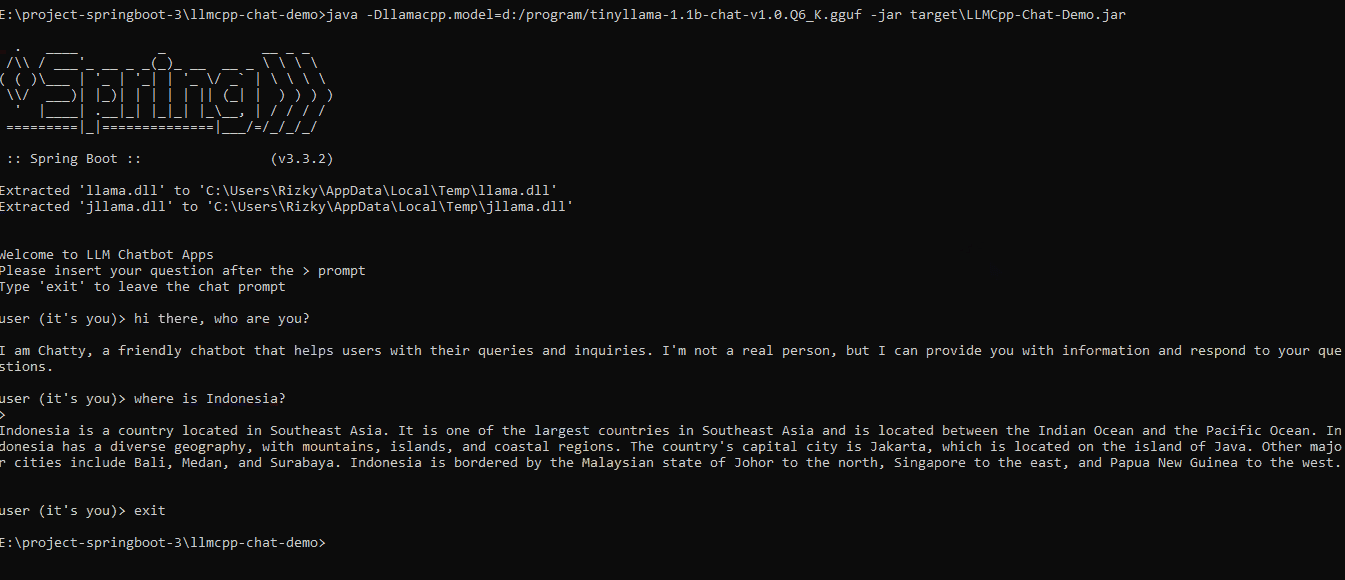
The flow of this interaction can be visualized as follows:
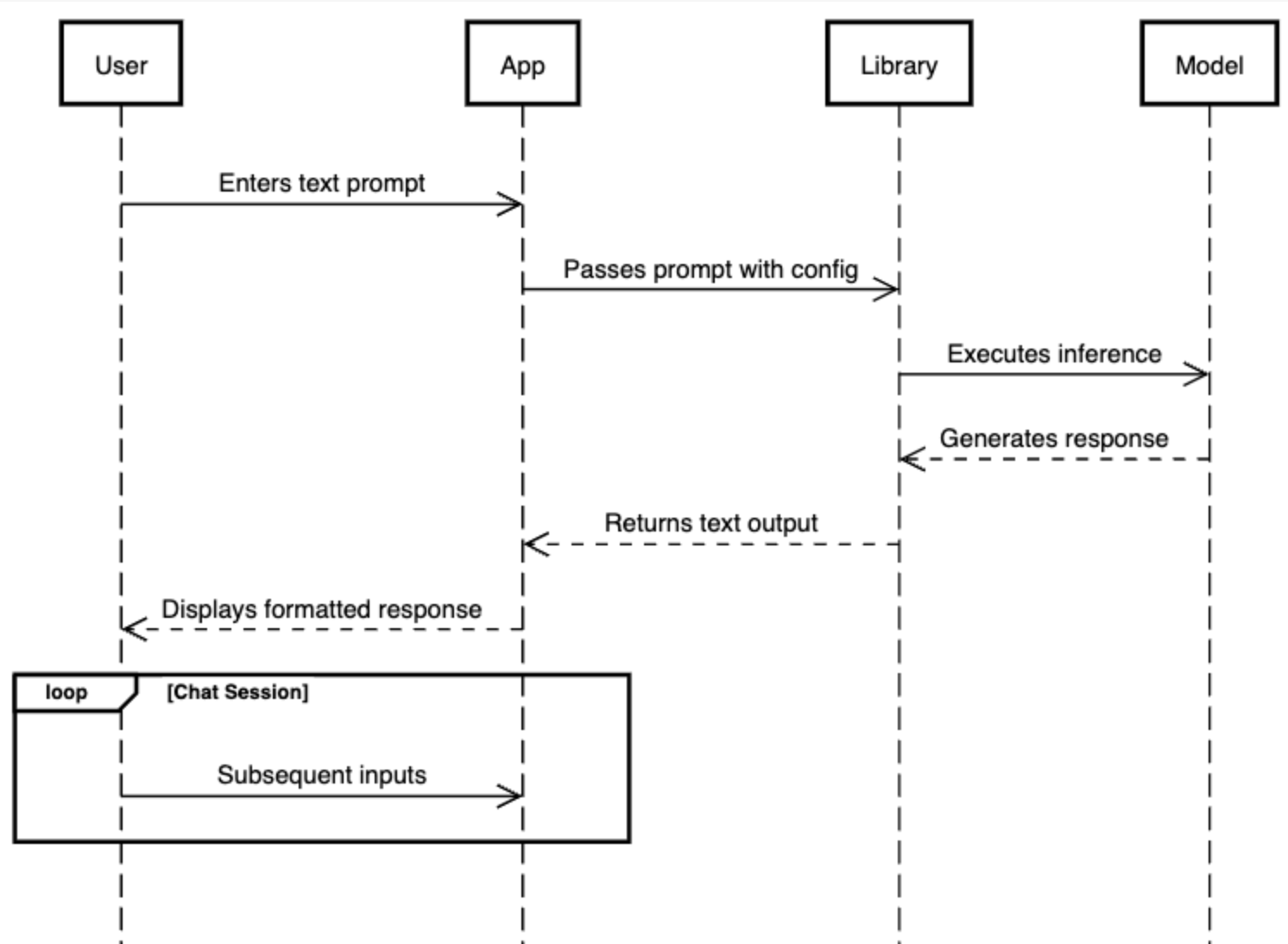
The app's architecture relies on several key components:
- User (CLI User) – input/output through terminal
- App (Spring Boot App) – manages application lifecycle and Dependency Injection
- Library (LlmCpp-Java) – this component serves as a bridge, utilizing Java Native Interface (JNI) to llama.cpp
- Model (GGUF Model) – the loaded GGUF model, which executes the LLM inference based on user prompts.
This design enables self-hosted LLM execution with minimal dependencies, and I think it's a good starting point for building more complex LLM-powered applications in Java. You can find more exciting detail through:
Cygen, a Retrieval-Augmented Generation (RAG) system
Introducing Cygen, our refined Retrieval-Augmented Generation (RAG) system. As you may recall, we explored the potential of RAG last year, and today, we're excited to showcase significant enhancements that elevate Cygen's capabilities.
Building upon our previous work, detailed in this article:
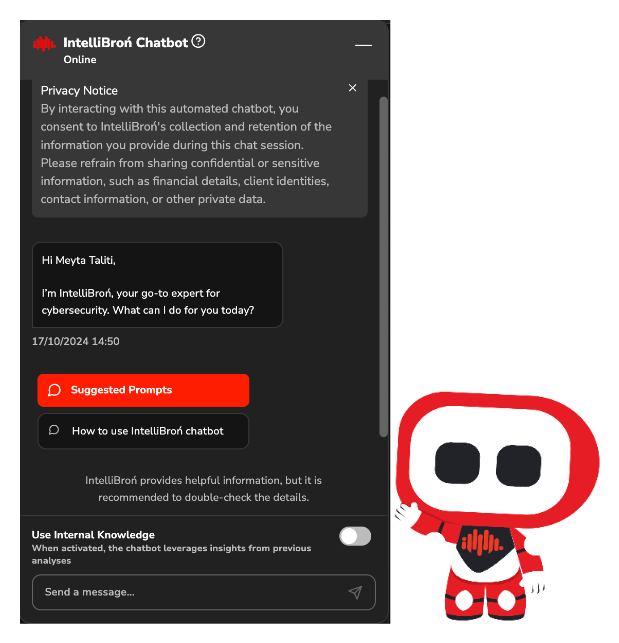
We've implemented a web-based user interface using Streamlit, providing a more intuitive and user-friendly interaction.
Key features include:
- PDF Document Ingestion: Processes PDF documents efficiently, even large ones, using multi-threading and background tasks. It intelligently breaks down the text into chunks.
- Smart Vector Search: Uses semantic similarity search to find relevant document chunks based on your questions, leveraging embeddings and metadata.
- Interactive Chat Interface: Allows real-time conversations with context window management and conversation history.
- Groq LLM Integration: Integrates with Groq's LLM for fast inference and uses optimized prompting strategies.
- User-Friendly Web UI: Provides a Streamlit-based interface for uploading documents, managing conversations, and chatting.
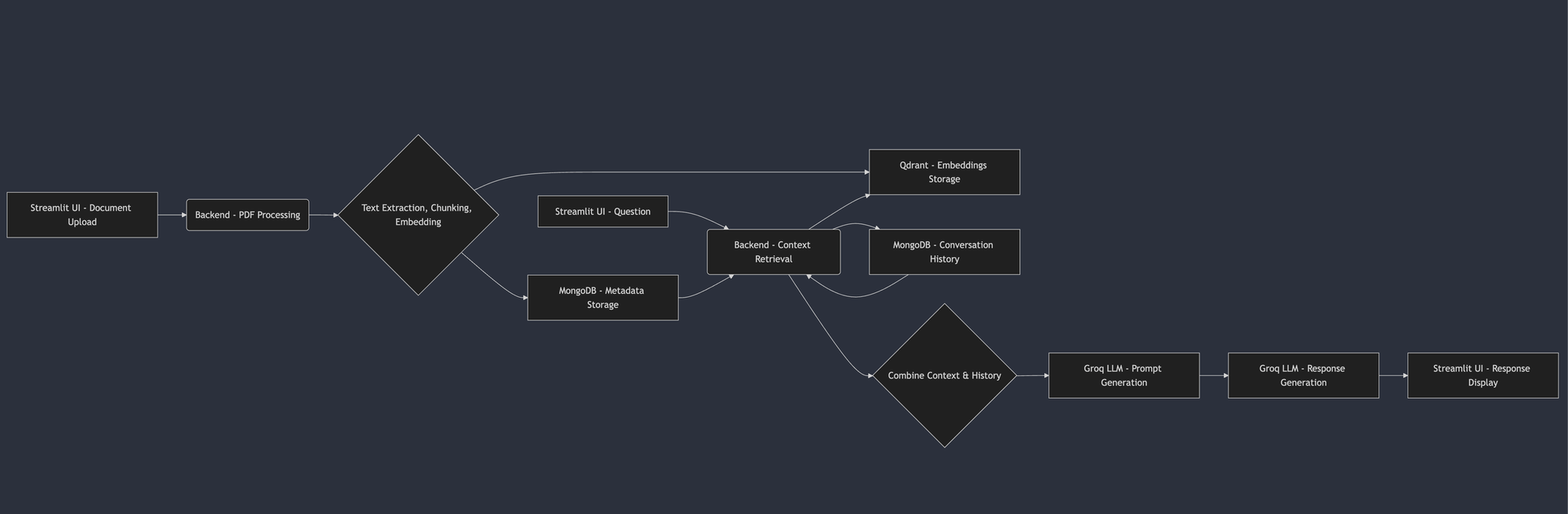
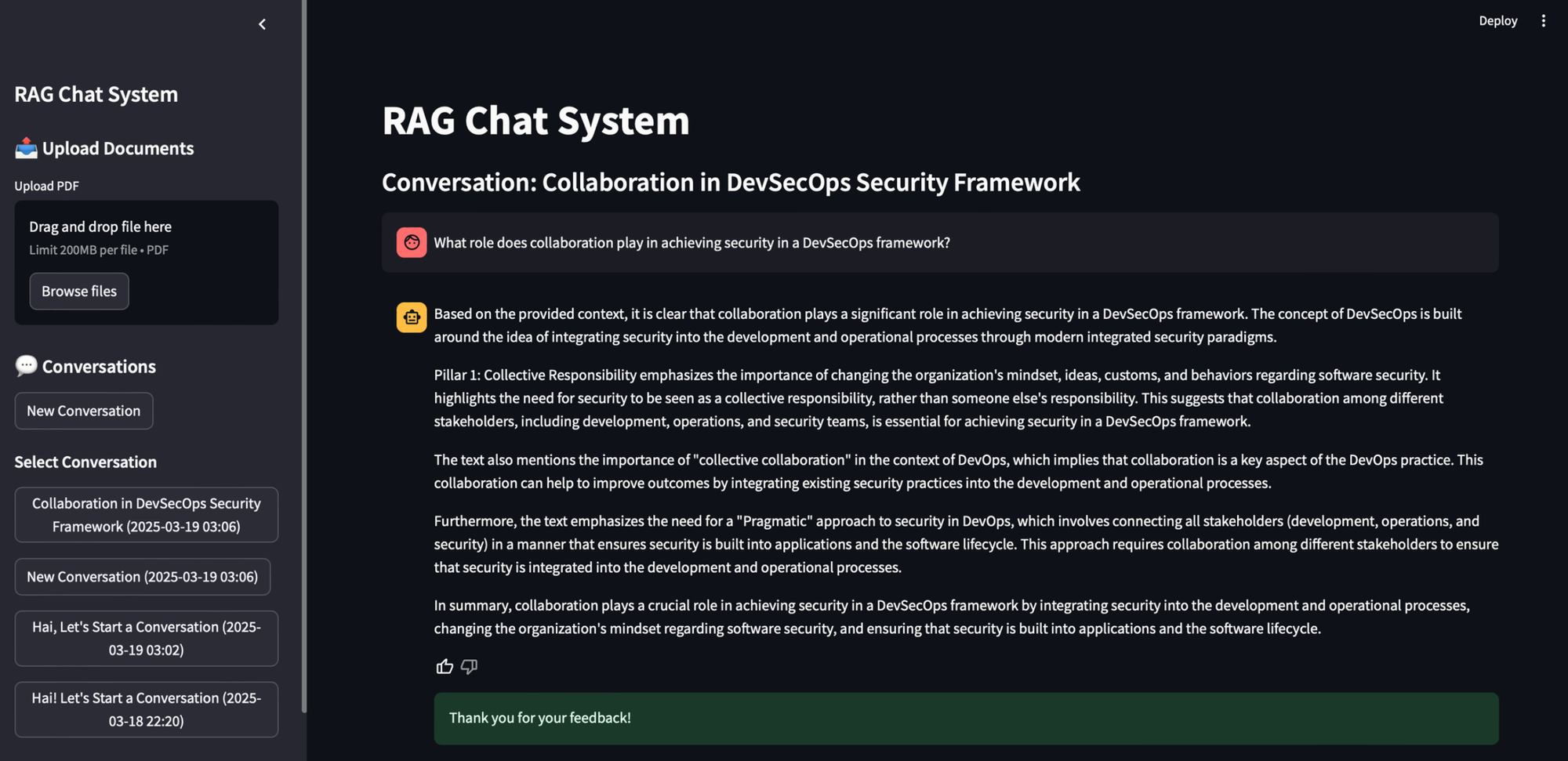
This functionality translates into a straightforward workflow:
- Document Upload: Begin by uploading a PDF document through the Streamlit user interface.
- Processing: The backend takes over, processing the PDF, extracting text, chunking it for efficient retrieval, and generating embeddings. These embeddings are stored in Qdrant for vector search, while metadata is stored in MongoDB for quick access.
- Question: You then pose your question through the user interface.
- Context Retrieval: Cygen uses your question to search for relevant document chunks within Qdrant, and it also retrieves your conversation history from MongoDB, ensuring context is maintained.
- Response Generation: The retrieved context and conversation history are combined to create a comprehensive prompt for the Groq LLM, which generates a coherent and informative response.
- Response Display: Finally, the generated response is displayed within the Streamlit interface, providing you with the information you need.
So, what's going on under the hood? Basically, to handle your PDFs, the system pulls out the text, cleans it up, breaks it into smaller pieces, adds extra info, turns it into numerical representations, and stores it. When you ask a question, it figures out what you're asking, grabs the relevant bits, filters out irrelevant stuff, puts it all together, crafts a prompt, gets the LLM to generate a response, and then sends it back to you. That's how Cygen makes sure you get good, on-point answers. You can find more exciting detail through:
Alright, that brings us to the end of our overview!
We've taken you through the technical aspects of both our Spring Boot LLM Chatbot and Cygen project, giving you a peek into our design and implementation. We really hope you've found these insights useful.
And just a quick heads-up, if you'd like to see Cygen in action, Alif Ramadhan presented it at a recent meetup!

You can find the presentation link here: Presentation Link.
Plus, if you're interested in the Spring Boot LLM Chatbot, feel free to reach out with any questions. We're always happy to share what we've learned!
See you in the next article 👋